Create a user defined function is one of the important features of Amazon Redshift cloud data warehouse. Amazon Redshift supports creating user defined functions. You can create custom user-defined functions (UDF) using either SQL SELECT statements or Python program. In this article, we will check Redshift user defined functions examples and how to create them.
Redshift User Defined Functions
User defined function (UDF) in Redshift provide a powerful way to perform complex data processing tasks within the Redshift database. They can provide more control and flexibility over data processing workflows, and potentially improve performance by reducing the amount of data transferred between the database and client application.
The custom user defined functions are bound to the database. Since Redshift does not support cross database access, you must create function on all required databases. Once a function is created, anyone with required privileges can execute the function. Amazon Redshift function performance is usually better as UDF’s reduce the amount of data transferred between the database and client application
Following is the syntax for creating Redshift custom function for data transformation:
CREATE [ OR REPLACE ] FUNCTION f_function_name
( { [py_arg_name py_arg_data_type |
sql_arg_data_type } [ , ... ] ] )
RETURNS data_type
{ VOLATILE | STABLE | IMMUTABLE }
AS $
{ python_program | SELECT_clause }
$ LANGUAGE { plpythonu | sql }
Redshift User Defined Functions Examples
Redshift Python Functions are custom user defined functions that allow you to write custom complex logic for custom calculations using the Python programming language. These functions can be used to perform complex data processing tasks that would be difficult or impossible to perform using SQL.
Now let us check some examples on how to create user defined function in Redshift:
Redshift User Defined Function using Python Examples
Following example demonstrates UDF using Python program:
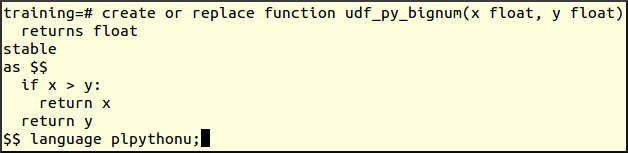
create or replace function udf_py_bignum(x float, y float)
returns float
stable
as $$
if x > y:
return x
return y
$$ language plpythonu;
--Call Created function
training=# Select udf_py_bignum(10.4,15.1);
udf_py_bignum
---------------
15.1
(1 row) Once Redshift database user defined function is created, you can can that using SELECT statement. Above example demonstrate how to create user defined function and call it using SQL statement.
Following is another Redshift UDF example to extract domain names from email address:
create or replace function udf_domain (email varchar(max))
returns varchar(max)
stable as $$
if not email:
return None
return email.split('@')[-1]
$$ language plpythonu;
--Call User defined function
training=# Select udf_domain ('user@dwgeek.com');
udf_domain
------------
dwgeek.com
(1 row) Redshift User Defined Functions using SQL Examples
Redshift SQL user defined functions are custom user defined functions that allow you to write custom complex logic for custom calculations using the SQL language.
Following example demonstrates UDF using SQL statements:
create or replace function udf_sql_bignum (float, float)
returns float
stable
as $$
select case when $1 > $2 then $1
else $2
end
$$ language sql;
--You can just call UDF as if you are calling built-in functions:
training=# select udf_sql_bignum(10.3,100.2);
udf_sql_bignum
----------------
100.2
(1 row) Once UDF with SQL statement is created, you can can that using SELECT statement. Above example demonstrate how to create user defined function and call it using SQL statement.
Restriction on using SQL clause in UDFs
The SELECT clause can’t include any of the following types of clauses in the statements:
- FROM
- LIMIT
- INTO
- WHERE
- GROUP BY
- ORDER BY
Nested User Defined Function in Redshift
You can create the UDFs by calling other UDFs. Redshift does not track the dependency while creating UDF. The nested function must exist when you run the CREATE FUNCTION command.
create or replace function udf_nested_func (float, float )
returns float
stable
as $$
select udf_sql_bignum ($1, $2)
$$ language sql;
--Call function
training=# select udf_nested_func(10.3,100.2);
udf_nested_func
-----------------
100.2
(1 row) Redshift supports nested functions i.e. calling function within another function.
What are the Advantages of Redshift SQL User Defined Functions?
Amazon Redshift user-defined function (UDFs) provide many advantages, such as:
- Code reuse: With the help of Redshift UDFs, you can define a piece of code once and use it in multiple SQL statements, This reduces code duplication, making your code more readable and maintainable.
- Custom logic: Redshift UDFs allow you to define custom logic in SQL or Python that is specific to your business requirements or data processing.
- Ease of use: You can use Redshift UDFs like any other built-in SQL function, making them easy to use for developers and other SQL users.
- Portability: You can move UDFs between Redshift databases and servers, allowing you to reuse your code across different systems.
- Improved performance: By encapsulating custom complex logic into a UDF, you can improve query performance and reduce the amount of code that needs to be written and maintained.
- Create SQL and Python UDFs: Redshift allow you to create a Redshift user-defined functions using either SQL or Python program.
Related Article
- Working with Amazon Redshift Stored Procedure
- Amazon Redshift isnumeric Alternative and Examples
- Amazon Redshift Validate Date – isdate Function
Hope this helps 🙂