Spark SQL uses Catalyst optimizer to create optimal execution plan. Execution plan will change based on scan, join operations, join order, type of joins, sub-queries and aggregate operations. In this article, we will check Spark SQL EXPLAIN Operator and some working examples.
Spark SQL EXPLAIN Operator
Spark SQL EXPLAIN operator provide detailed plan information about sql statement without actually running it. You can use the Spark SQL EXPLAIN operator to display the actual execution plan that Spark execution engine will generates and uses while executing any query. You can use this execution plan to optimize your queries.
Related reading – Spark SQL Performance Tuning
Spark SQL EXPLAIN operator is one of very useful operator that comes handy when you are trying to optimize the Spark SQL queries. You can use the EXPLAIN command to show a statement execution plan.
Spark SQL EXPLAIN Operator Syntax
Below is the syntax to use the EXPLAIN operator:
EXPLAIN [EXTENDED | CODEGEN] sql_statementEXTENDED:Output information about the logical plan before and after analysis and optimization. This option generates Parsed Logical Plan, Analyzed Logical Plan, Optimized Logical Plan and Physical Plan
CODEGEN: Output the generated code for the statement, if any. Sometime codegen will throw an exception.
By default, EXPLAIN operator only outputs information about the physical plan.
Note that, Explaining 'DESCRIBE TABLE' is not supported.
Spark SQL EXPLAIN Operator Example
Below is example that explains how execution plan looks like:
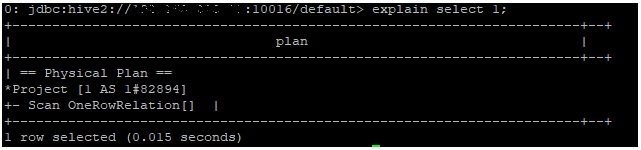
> explain select * from item;
| == Physical Plan ==
HiveTableScan [i_item_sk#82840, i_item_id#82841, i_rec_start_date#82842, i_rec_end_date#82843, i_item_desc#82844, i_current_price#82845, i_wholesale_cost#82846, i_brand_id#82847, i_brand#82848, i_class_id#82849, i_class#82850, i_category_id#82851, i_category#82852, i_manufact_id#82853, i_manufact#82854, i_size#82855, i_formulation#82856, i_color#82857, i_units#82858, i_container#82859, i_manager_id#82860, i_product_name#82861], MetastoreRelation testtdb, item |
Understand Spark SQL EXPLAIN Plan
Below are some of the features that are available in Spark SQL plan:
| Feature Name | Description |
| Sort | Number of Sort |
| Exchange rangepartitioning | range partitioning |
| Project | Number of select statements |
| SortMergeJoin | Inner Joins |
| Exchange hashpartitioning | Hash Partitioning |
| HashAggregate | Aggregate Functions |
| BroadcastHashJoin | Join condition in case of non co-located tables |
| Filter | Where condition |
| HiveTableScan | Table scan operation |
| MetastoreRelation | Number of relations in given query |
| BroadcastExchange HashedRelationBroadcastMod | Casting function |
| TakeOrderedAndProject | WITH Clause feature |
| Scan OneRowRelation | Single row query without any relation |
| CollectLimit | Limit Clause in query |
| Window | Analytics Fucntions |
| Inner | Inner Join |
| LeftOuter | left outer join |
| RightOuter | Right outer join |
| CartesianProduct | Cartesian or cross Join |
| BroadcastNestedLoopJoin | Nested loop join |
| BroadcastExchange IdentityBroadcastMode | Broadcast join |
| CreateTableCommand | Create table |
| DropTableCommand | Drop table command |
| AlterTableRenameCommand | Alter table |